Language technology tools to support low-resource languages: case study of Sakha

Sardana Ivanova

2022-05-16
Contents
- Sakha language
- A free/open-source morphological analyser and generator for Sakha
- Sakha in Revita—computer-assisted language learning platform
- Poetry generation
- Template-based news generation
- Work in progress: Turkic benchmark
- Conclusions
Sakha
- Turkic language
- ~450K speakers
- Spoken primarily in Siberia
- Official status in Sakha Republic
- Entire area prone to economic and cultural impacts of climate change
- Agglutinating — words may be inflected using a series of affixes
- Backness and rounding vowel harmony systems
- Word order: Subject-Object-Verb
- Lena Turkic:
- dlg - Dolgan
- sah - Sakha
- Sayan Turkic:
- dkh - Dukha
- kim - Tofa
- tuh - Tuha
- tyv - Tuvan
- Yeniseian Turkic:
- cjs - Shor
- clw - Chulym
- fyg - Fu-yü Gyrgys
- kjh - Khakas
- tuh - Tuha
- Altay Turkic:
- alt - Altay, Teleut, Telengit
- atv - Chalqan, Qumandy, Tuba
- tlt - Bachat Teleut
- Kypchak (NW) Turkic:
- sty - Siberian Tatar
A free/open-source morphological analyser and generator for Sakha
Joint work with

Jonathan N. Washington¹

Francis M. Tyers²,³
- Swarthmore College, USA
- Indiana University, USA
- Высшая Школа Экономики, Москва


Morphological tranducers
- Twofold function: morphological analysis and generation
атын ↔ атn px3sg acc /атынadj /атынpost - Implemented as finite state transducers (FST)
- Compiled from hand-coded lexical, morphotactic, and morphophonological generalisations
- Only one development cycle
- many uses in language technology and ``downstream'' tasks:
- can be repurposed as spell checkers
- may be used in rule-based machine translation pipelines
- Some current uses of this transducer
- used in Revita—language learning platform for revitalization and support of endangered languages (Katinskaia et al., 2018)
- used to generate data in recent shared task on morphological reinflection (Pimentel et al., 2021)
Existing Turkic transducers
Comparison of lexicon size
 Production-level
Production-level92%-98% coverage
(Tatar, Sakha, Kazakh, Turkish, Kyrgyz, Crimean Tatar, Tuvan)
 Working
Working88-93% coverage
(Chuvash, Uzbek, Bashqort, Qaraqalpaq, Uyghur, Karachay-Balkar, Gagauz, Kumyk)
 Prototype
Prototype<80% coverage
(Azerbaycani, Turkmen, Iraqi Türkman, Noghay, Khakas, Altay, Ottoman)
Implementation and Challenges
Two-level approach using HFST
orthographic form
дьиэлэрбиттэн↕ (twol: phonological mappings)
morphological/lexical form
дьиэ>↕ (lexc: lexicon + morphotactics)
analysis: lemma, POS, grammatical tags
дьиэImplementation and Challenges
Vowel harmony with diphthongs and long vowels
Problem:
- Sakha long vowels (
I I ,A A ) behave like short-vowel counterparts - But diphthongs (
I A ) behave like high vowels (I )
(round after any round V, do not trigger rounding of low Vs)
Solution:
- Each
twolharmony rule (char-to-char mapping): sensitive to whether harmonising V is component of long V or diphthong or not - Many V harmony alternations required multiple rules to implement
Implementation and Challenges
Two-directional consonant assimilation
Problem:
- forms like /tutn-bIt-A/ ‘use-
past -3 ’ realised as [tutummuta]
тутy н>B I т>A :тутуммута - /n/ triggers nasalisation of the following /b/
- /b/ triggers labialisation of the preceding /n/
Solution:
- Mutual influence not problematic in
twol - rules are sensitive to underlying form (left side of :) of adjacent symbol, not surface form (right side of :)
Implementation and Challenges
Many alternations in a single stem
Problem:
- forms like уһун ‘swim[
imp ]’ / устар ‘swim-pres ’ - Several different alternations involved:
с ~ Һ— intervocalic lenitionн ~ т— sonority restrictionsI ~ ∅
Solution:
- ≥1
twolmapping for each alternation - each mapping sensitive to the others & to other parts of morphophonological context
y used for high vowel ~ ∅ alternation, as in previous work (Washington et al., 2019)
Implementation and Challenges
Novel grammatical understanding
Existing literature:
- Sakha exhibits many non-finite verb forms
- Some have finite uses
- Generally categorised roughly as "participle" or "converb"
Our contribution:
- Categorised each form carefully based on uses:
verbal noun, verbal adjective, verbal adverb, infinitive - Implemented each use separately
- Results in some syncretism (forms existing across multiple categories)
- Concluded that there is not a strict participle/converb dichotomy
- Documented in more detail in Washington et al. (2021)
Evaluation
Coverage
- Naïve coverage: the number of forms in a corpus that receive an analysis, regardless of whether or not the analysis is correct (e.g., in context)
| Corpus | Tokens | Coverage |
|---|---|---|
| Newspapers | ~16M | 91.04% |
| Wikipedia | ~2.4M | 91.30% |
| New Testament | ~190K | 94.53% |
Over 90% coverage: robust morphology
Evaluation
Precision & Recall
- created gold standard:
- 1000 valid words of Sakha
- randomly selected from Wikipedia corpus
- manually annotated output of transducer
| Corpus | Precision | Recall |
|---|---|---|
| Wikipedia | 98.52% | 75.42% |
i.e., nearly every form returned by the transducer was deemed correct, but many correct analyses were not returned by the transducer (mostly due to low coverage)
Future work
- Correct minor issues in implementation of some morphophonological alternations
identified recently in data generation for a shared task (Pimentel et al., 2021) - Morphological/syntactic disambiguation
- More language technology applications of transducer? (spell checkers, MT, etc.?)
Conclusion
- Robust transducer
- high coverage
- high precision
- moderate recall
- Lots of room for improvement!
- Ready for use in language technology applications, downstream tasks
- This work has also contributed to documentation of Sakha grammar
- Fork at github.com/apertium/apertium-sah
- Try out at beta.apertium.org
Revita
Computer-Assisted Language Learning system
A project of the Language Learning Lab at the University of Helsinki
Revita
Computer-Assisted Language Learning system
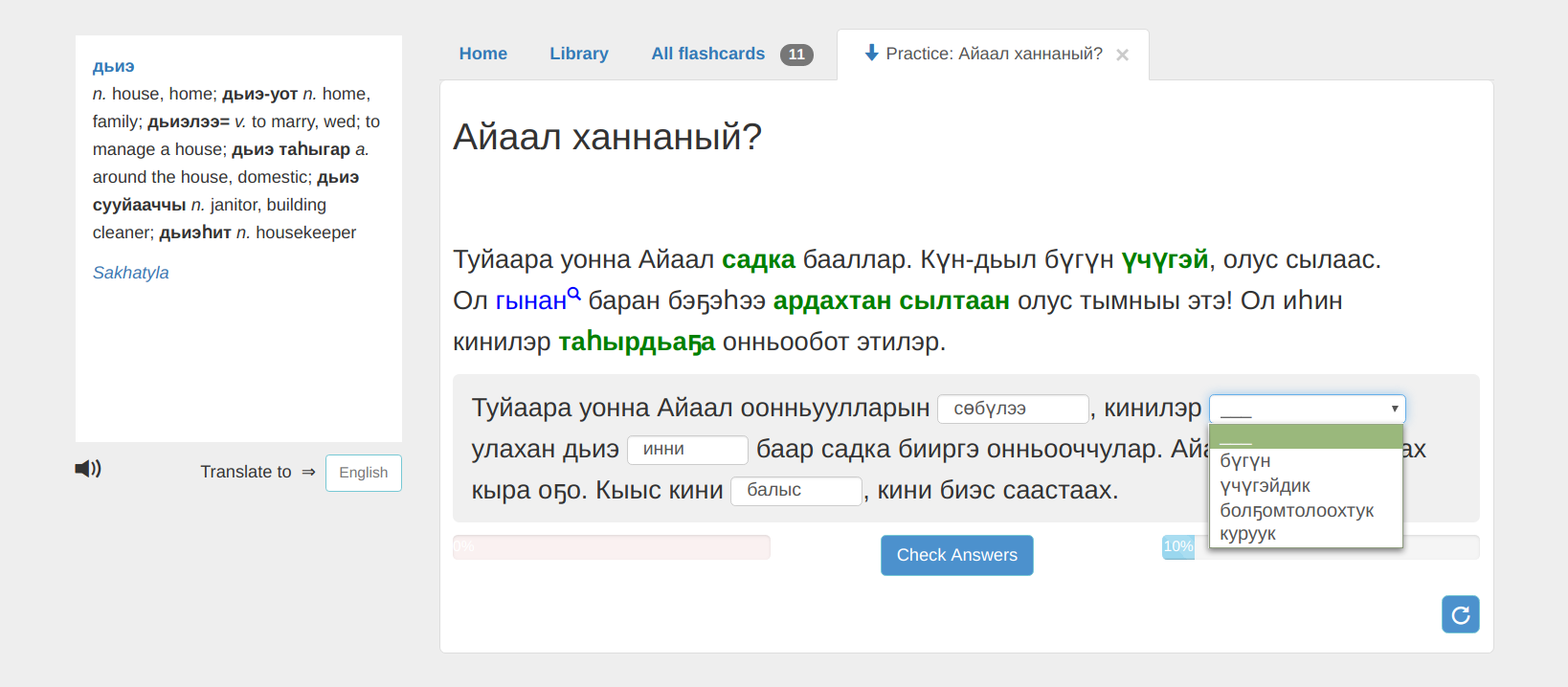
- User uploads arbitrary text
- System generates exercises
- User practices with exercises
- System gives feedback
Revita modules
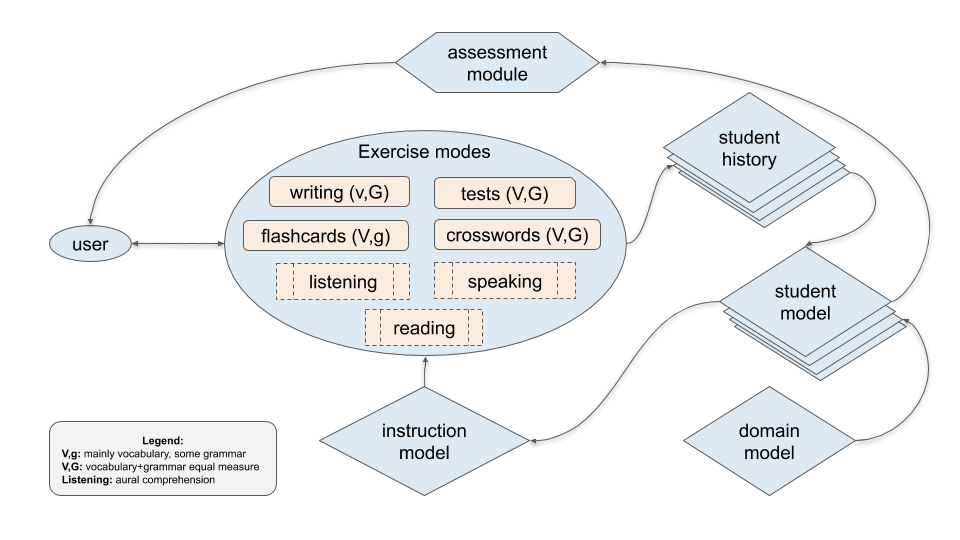
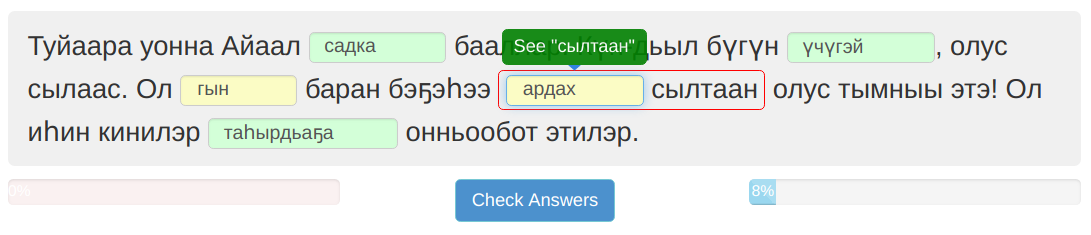
Conclusion
- The functionality of the language learning system is under development. For languages with more speakers many more linguistic resources and tools are available than for Sakha.
- For example, currently, the Sakha system has only noun–postposition government rules.
- Try out at https://revita.cs.helsinki.fi
Poetry generation
Joint work with
- Michele Boggia
- Anna Kantasalo
- Simo Linkola
- Hannu Toivonen
Poetry
There Will Come Soft Rains
Sara Teasdale - 1884-1933
There will come soft rains and the smell of the ground,
And swallows circling with their shimmering sound;
And frogs in the pools singing at night,
And wild plum trees in tremulous white,
Robins will wear their feathery fire
Whistling their whims on a low fence-wire;
And not one will know of the war, not one
Will care at last when it is done.
Not one would mind, neither bird nor tree
If mankind perished utterly;
And Spring herself, when she woke at dawn,
Would scarcely know that we were gone.
Interaction pattern

Both models are fine-tuned mBART models
Data
- English
- Gutenberg project
- Finnish
- Gutenberg project
- Wikisource
- Modern poetry from Poesia publishing house
- Swedish
- Wikisource
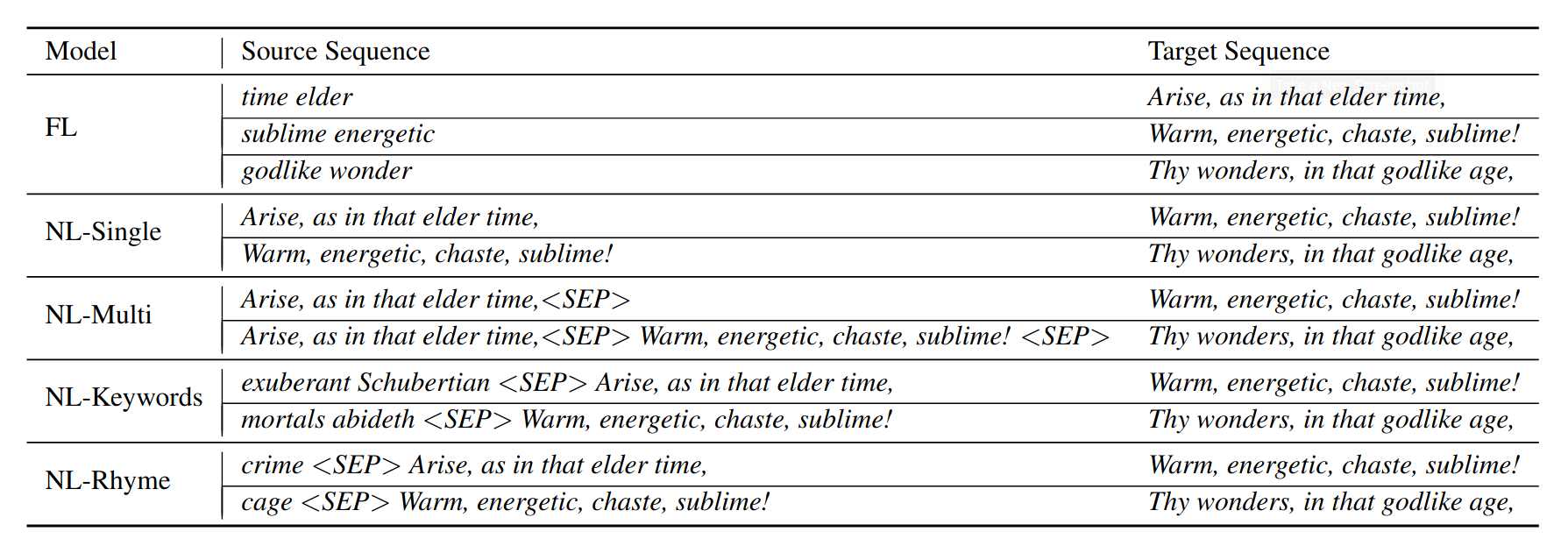
Conclusion
- Simple co-creative poetry generator system
- The highly limited interaction on purpose
- The system generates lines using fine-tuned mBART models
- The next step is an evaluation of the system and measures with actual users
- Fork at github.com/bmichele/poetry_generation
- Try out with @boetry_bot on Telegram
Template-based news generation
Part of the Embeddia project
Cross-Lingual Embeddings for Less-Represented Languages in European News Media
Template-based news generation
CPHI (Harmonized Index of Consumer Prices)
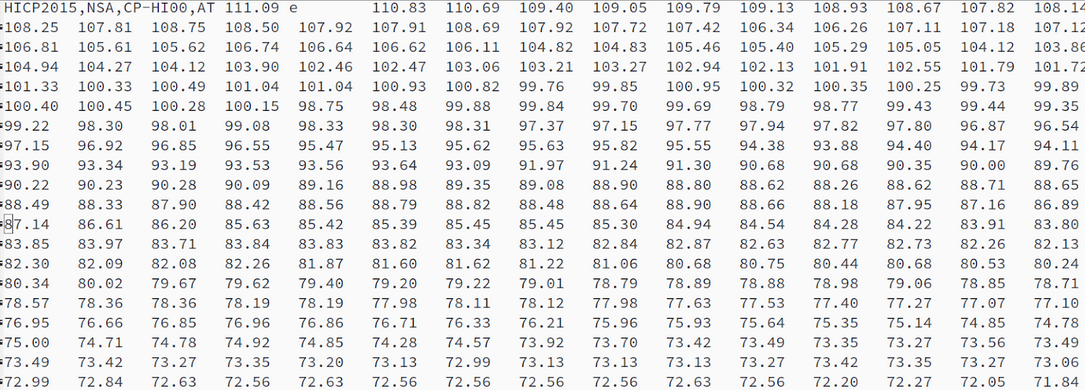
Template-based news generation
Template example

Template-based news generation
Result example
В Апреле 2021, в Финляндии, ежемесячный темп роста согласованного индекса потребительских цен для категории 'здоровье' был 2.5 пункта. Ежемесячный темп роста согласованного индекса потребительских цен для категории 'здоровье' был на 2.3 процентных пунктов больше, чем в среднем по ЕС. В Марте 2021, ежемесячный темп роста согласованного индекса потребительских цен для категории 'здоровье' был на 2.2 процентных пунктов больше, чем в среднем по ЕС. Ежемесячный темп роста согласованного индекса потребительских цен для категории 'здоровье' был 2.3 пункта. Финляндия имела 2 самый высокий ежемесячный темп роста согласованного индекса потребительских цен для категории 'здоровье' во всех наблюдаемых странах. В Апреле 2021, Финляндия имела 1 самый высокое значение во всех наблюдаемых странах.
Turkic benchmark
A project of Turkic Interlingua community
The goal is to create benchmarks for Extractive Summarization, SQuAD Question Answering, NLI, NER, and some other tasks for 23 Turkic languages
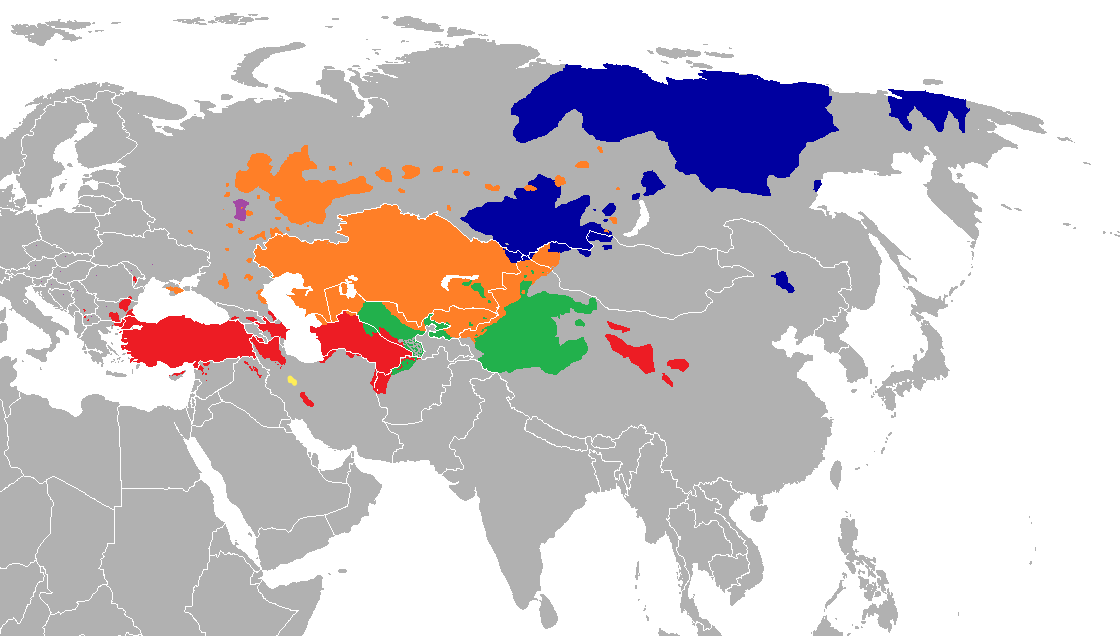
List of languages
- Altai
- Azerbaijani
- Bashkir
- Chuvash
- Crimean Tatar
- Gagauz
- Iraqi Turkmen
- Karachay-Balkar
- Karakalpak
- Kazakh
- Khakas
- Kirghiz
- Kumyk
- Sakha
- Salar
- Shor
- Tatar
- Turkish
- Turkmen
- Tuvinian
- Urum
- Uyghur
- Uzbek
Conclusions
- A free/open-source morphological analyser and generator for Sakha
- Sakha in Revita—computer-assisted language learning platform
- Poetry generation
- Template-based news generation
- Work in progress: Turkic benchmark
Махтал! / Maxtal! / Thank you!